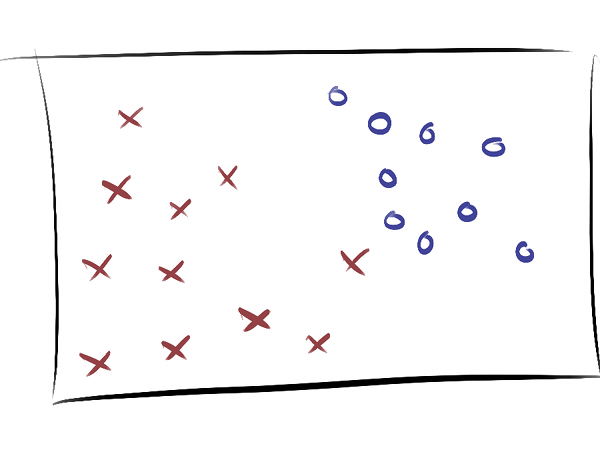
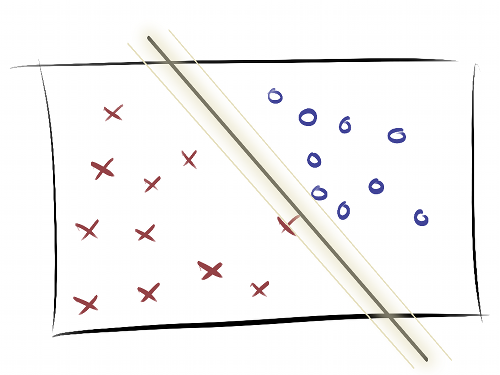
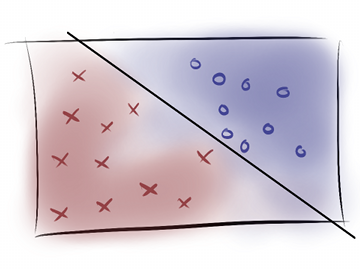
Training and testing on the same data leads to overfitting.
Better idea: Train & test on different subsets of the data!
K-fold: Split data into N parts, use N-1 for training and 1 for testing.
Average out the N results.
Excellent way to select parameters (such as alpha) without overfitting
from sklearn import cross_validation
# Ten fold cross validation has been shown to avoid overfitting in most cases
kf = cross_validation.KFold(len(data), k=10)
for train_index, test_index in kf:
train_feats, test_feats = data[train_index], data[test_index]