
It's ML, not magic: machine learning can be prejudiced
July 30, 2016
Of the many misconceptions about machine learning, the idea that they can't be prejudiced is likely the most harmful. As stated by Moritz Hardt in How big data is unfair, machine learning is not, by default, fair or just in any meaningful way. Even though many researchers and practitioners have noted this repeatedly in the past, the message is still lost. It's not uncommon to hear variations of "algorithms don't have in-built bias" even when there is an entire field of research dedicated to fighting that very issue.
To make this clearer, prejudice in machine learning will haunt us for years to come. Prejudice in machine learning is like security in programming. No-one will notice the underlying issues until it's obvious something is horribly wrong. By the time we hit this realization, the flaws might have negatively impacted hundreds of thousands in a way that can't be undone. Even worse, competence is no guarantee you will be able to prevent these issues from occurring.
Ask yourself whether you think the machine learning teams at Google are competent (hint: they are). Then consider that black people were tagged as gorillas and that Google's speech recognition works better for men than for women. The Google Photos incident, whilst a horrible and upsetting blunder, was fixed quickly after it became obvious. The latter is insidious however - the issue is not necessarily obvious but represents a consistent negative penalty that impacts specific groups for the simple reason that they're not the majority or targeted class.
If we're not careful, optimizing life for some will be equivalent to handicapping life for others. Those others tend to be minority classes or the non-targeted demographics, as is the case with the gender bias above.
To reiterate, I only picked on Google as they have some of the most competent people on earth in machine learning. Most companies that implement machine learning don't have anywhere near that level of quality available - and that's a terrifying prospect. As with computer and network security, high levels of competence provides no guarantee you can avoid prejudice leaking in to your systems. When machine learning systems are built by teams with less knowledge or less care, the results will be even more tragic.
(I'm biting my tongue by not mentioning Microsoft Tay in any more detail...)
Many might argue that, when we have perfected these algorithms, the results they give will be less biased. I am not arguing against this eventual goal. That future may well be possible and likely represents a net benefit for society. I am simply arguing that, at present, we don't have the tools, theory, or sound practice to avoid prejudice in many sensitive applications of machine learning.
Machine learning is eating the world
First though, why is being wary of prejudice in machine learning important? Machine learning already has an impact on many fundamental aspects of our lives. The reach of automated decisions will only be expanding as we progress into the future. Right now there are automated algorithms deciding on the content you are shown, the loans you may be offered, the rates you receive for life insurance, whether your resume is automatically filtered out of the recruiting process, or whether you are likely to commit a crime ... And all of this is just the beginning.
(Note: predicting whether you are likely to commit a crime was what pushed me over the edge to write this - the general consensus of many machine learning experts on my feed was terror whilst the model used features that could easily leak race and only lightly mentions the potential concerns)
These systems don't need to be complicated in order to impact us negatively. They may be systems and algorithms that we've had in existence for decades. As these systems become more complex however they also become even more difficult to debug.
The simple machine learning frameworks that have become increasingly popular over the recent past are a double edged sword. I am genuinely excited that so many people can learn about our field - this is truly brilliant! What disturbs me however is that best practices may not be followed whilst machine learning is applied to progressively more and more sensitive applications.
If we're not careful, the cumulative bias in these systems might dictate the direction of people's lives. Those most adversely effected are also likely those in our society who are already maligned, not those protected in the majority class or with the power or influence to challenge such decisions.
What can be done?
What do we need to solve this? Hoping for some level of explicit certification is insane. It likely wouldn't be altogether effective and even if it was, you don't need any level of certification to work on the code for a nuclear power plant, you're unlikely to need certification for implementing machine learning. There are attempts however.
The European Union has introduced regulations to restrict automated individual decision-making which "significantly affect" users and also the "right to explanation" whereby a user can ask for an explanation of an algorithmic decision that was made about them. Many machine learning researchers and practitioners were surprised (and some even annoyed) by this. The laws as they stand are loose and will result in many problems but they do make obvious the potential flaws that our nearing future may introduce. It's scary to admit, but a fundamental issue is that for many machine learning models, there does not exist a consistent, reliable, or interpretable way to "explain in human" the resulting prediction. The regulation by necessity calls out a shortcoming of our field. If you're interested in further discussion, the implications are touched on European Union regulations on algorithmic decision-making and a "right to explanation".
There may be a need for the equivalent of the Open Web Application Security Project (OWASP) except for machine learning. Ensuring necessary but not sufficient steps are taken, such as balanced datasets, removal of explicitly sensitive features (and removal or processing of features that are highly correlated to those), proper dataset hygiene (training, validation, test, cross validation where necessary, ...), and so on. Even then, OWASP provides many of the best practices in computer and network security, yet the average application is horrendously insecure due likely to the most obvious and common of faults. The same is likely true of machine learning systems - knowing about and attempting to implement best practices is likely not enough.
tl;dr for prejudice in machine learning
- Any machine learning algorithm, regardless of the complexity, can result in prejudice
- Nothing in standard machine learning governs that the results should be unbiased
- Biased data in means biased data out
- Machine learning algorithms do better the more data they receive, which naturally results in majority classes getting more accurate results (see: speech recognition)
- Defining, quantifying, and avoiding prejudice in sounds ways is still an open research question in machine learning
- Ignorance of the intricacies within your model isn't an excuse - it's just gross negligence
- The interaction becomes even more unpredictable when these systems are deployed and the model's predictions may direct the distribution of future training data
A quick (insanely non-exhaustive) list of potential issues
Protected features (i.e. race / gender / ...) can be recovered from other features
If you want to avoid using gender or race as a feature in your classifier, removing the feature isn't enough. Machine learning models with sufficient representational capacity are able to reconstruct them from variables that are correlated with the protected features.
The easiest example of this is redlining, wherein discriminating against residents of certain geographical areas is an easy way to perform racial or ethnic discrimination. While identified long ago as a problem in the 1980s
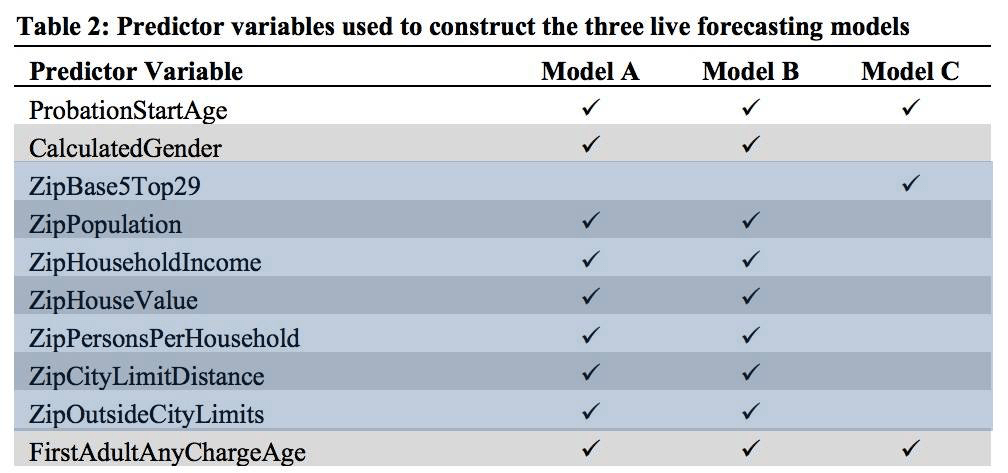
In the models explored in Classifying Adult Probationers by Forecasting Future Offending (PDF), the initial models take the person's zip code and uses that zip code's house value + household income + distance out of the city limits as features. Model C, currently in use for live prediction, replaces these with ZipBase5Top29 which is either the 29 most prevalent valid zip code values among probation cases or, in the case their zip code is not listed, 99998 if their zip code is in the city limits and 99999 if they are outside.
Given courts are allowing black box algorithms to be used for risk assessment, this is a very scary direction indeed. The incentive for someone to add a feature that may improve accuracy but in an unfair way for some of the impacted, especially when the model won't be externally audited, can't be missed.
Bias within word vectors
Word vectors sit at the base of many recent NLP models, yet the models don't just capture useful semantic information (king is to male as queen is to female), it also captures stereotypes and gender bias that are painfully obvious. If we give these word vectors to models in order for the model to use the embedding information, surely we must be concerned if these aspects are captured?

What to do when word vectors exhibit such biases is not even clear. Word vector models are generally trained on datasets of billions of words, acquired from a variety of sources. As such, there is no way to "clean" such a large and complicated dataset. Even when there exist methods to debias the word vectors, there is debate as some believe that "ML algorithms should tell the truth, and we should decide what to do with it, not tamper with the evidence".
Biased training data
There have been proposals and even implementations that use machine learning for resume filtering. The general argument that this helps fight bias frequently goes like this:

As stated earlier, there is nothing about machine learning that guarantees no bias - even if the data wasn't biased.
As stated by the paragraph above, human based hiring procedures are indeed biased. What do we train our machine learning systems on however? Training data obtained from humans. That means that, on top of all of the issues above, the machine learning model will learn to capture the existing biases, such as favoring Anglo-Saxon names when considering identical resumes.
Minorities treated differently than the majority
Modern machine learning is data driven. The more data you have access to, the better. By definition, we generally have less training data for minorities compared to the quantity of training data for the majority class. Less data results in a worse model for that class, especially as the methods learned for the majority class may not work well at all for the minority class.
If this is mixed with an unbalanced dataset below, we have a major problem. Getting 99% correct on a test composed of addition and multiplication questions doesn't mean much for your ability to multiply if 99% of the questions were for addition.
Unbalanced training data
Want to find seven people out of the population of an entire country? This doesn't work. This just really frakking doesn't work. Using such an obviously flawed model as any basis for prediction, let alone for launching a drone strike against a person, is horrendous.

Unfortunately, this issue can still exist even when the datasets are far larger or the model used for more innocuous tasks.
Additional reading
People far smarter than me have discussed these issues in detail before. Both of the following articles provide a brilliant general introduction to some of the potential issues that might arise. There is then a world of research beyond if that's your speed!
- How big data is unfair: understanding unintended sources of unfairness in data driven decision making
- Big Data, Machine Learning, and the Social Sciences: Fairness, Accountability, and Transparency
Thanks to:
- Nick Nguyen for his lovely card shot shared under Creative Commons BY-SA
- Anton Troynikov for pre-reading the article and sharing refinements

Popular Articles
- It's ML, not magic: machine learning can be prejudiced
- It's ML, not magic: the rise of AI-prefix investing
- In deep learning, architecture engineering is the new feature engineering
- How Google Sparsehash achieves two bits of overhead per entry using sparsetable
- Where did all the HTTP referrers go?
Interested in saying hi? ^_^
Follow @Smerity