Stop saying DeepCoder steals code from StackOverflow
February 26, 2017
This is a hard topic to cover. I know a number of journalists and appreciate their work in communicating these advances to a wide audience. It's a hard job to convey complex concepts and in many cases they're not at fault for how it becomes warped by the broader community. Sadly, regardless of the exact way these research stories are warped, most AI and ML stories in the media will result in an audibly groan from researchers.
As a researcher in the rapidly progressing field of machine learning, I see no need to fictionalize the tremendous advances we see. I believe AI hype actively harms us both academically and commercially. It's not just that this misrepresentation provokes potential retaliation from AI winters long since past, it's that facts are actively discarded from science in order to craft a romanticized but entirely inaccurate fiction. As I previously wrote, combating this fictionalization of research and the prevalance of AI hype should be a top priority.
DeepCoder is an excellent example of the slow decay from an originally well researched story to meandering. While the DeepCoder paper is interesting and worthy of merit, the research became a caricature of itself as it was replicated throughout the media. Heralded by many as a new advance in February 2017, the paper was in fact first released in early November 2016. This may have been as it was accepted to ICLR in early February, though this doesn't justify the rapid fictionalization it endured. If you're interested in hearing the unfiltered thoughts of the official reviewers and other researchers in the field, the ICLR comments are hosted publicly on OpenReview.
In this article, we first break down the DeepCoder work in terms of what it contains, then we explore how it became progressively misconstrued in the media, and finally we produce a new version of the DeepCoder article that aims to be broadly understandable whilst trying to avoid any fluff. If you're interested in only the latter two, you can safely skip downwards.
What's the task?
Defining the machine learning task in academia is vitally important. Such definitions help understand the scope of the problem and the limits involved in any potential solution.
In the standard programming competition setting, you're given two pieces of information:
- A textual description of the problem
- One or more example input / output pairs
A simple example from the paper is provided below.

Important note: DeepCoder doesn't use textual descriptions for generating a solution - it only uses the input and output pairs. See the section "Neural networks are better than infinite monkeys" below.
From this, your goal is to produce a working program that is (a) consistent with all provided input / output examples and (b) consistent with the task as described. Notice that solving (a) does not imply (b). All programmers will have run into this in the past - specifically when their examples don't cover edge cases they'd never considered and may not have written tests for.
This task is known as Inductive Program Synthesis (IPS): given input-output examples, produce a program that has behavior consistent with the examples and the defined task. For this work we'll assume that if the program solves all the examples, it's satisfactory. Obviously this assumption becomes a major liability if we were to transition IPS to the real world.
What does DeepCoder do?
The program space with our infinite monkeys
In the experiments in the paper, each problem is given five example input / output pairs. DeepCoder defines a domain specific language (DSL) that, when composed together, can solve the specified problems. This domain specific language contains 34 different first order and higher order functions and allows all integers from -255 to 255. Essentially, you have a set keyboard of options that you can use to piece together a solution.
First-order functions: HEAD, LAST, TAKE, DROP, ACCESS, MIN, MAX, REVERSE, SORT, SUM Higher-order functions: MAP, FILTER, COUNT, ZIPWITH, SCANL1. Higher-order MAP allows: (+1), (-1), (*2), (/2), (*(-1)), (**2), (*3), (/3), (*4), (/4) Higher-order FILTER and COUNT allows: (>0), (<0), (%2==0), (%2==1) Higher-order ZIPWITH and SCANL1 allows: (+), (-), (*), MIN, MAX
Note that this DSL does not contain any explicit control flow such as for loops, while loops, or branching.
This results in an enormous potential set of programs - one of which is guaranteed to hold the solution. This is referred to as the program space and is equivalent to throwing the infinite monkey theorem at the problem.
If you had an infinite number of monkeys all in front of specialized keyboards - buttons labeled with functions (SORT, TAKE, SUM), variables (k, b, c), and so on - one of the monkeys would eventually produce the correct program. Obviously monkeys are slow, temperamental, and require bananas, so we'd hope there's a better option.
One of these better options is depth first search (DFS), where we weight the search towards programs similar in composition to previous working programs we've seen in training and keep testing the program against the input / output examples to see if it works. This is one of the baselines that DeepCoder competes against. Given infinite time (less infinite time than the monkeys need though), DFS would solve our proposed problems using the DSL specified above.
Neural networks are better than infinite monkeys (but way less fun)
DeepCoder reads the input and output example pairs and predicts the presence or absence of individual functions from the DSL.
Important note: DeepCoder doesn't even read the problem description yet to help decide which functions are most likely!
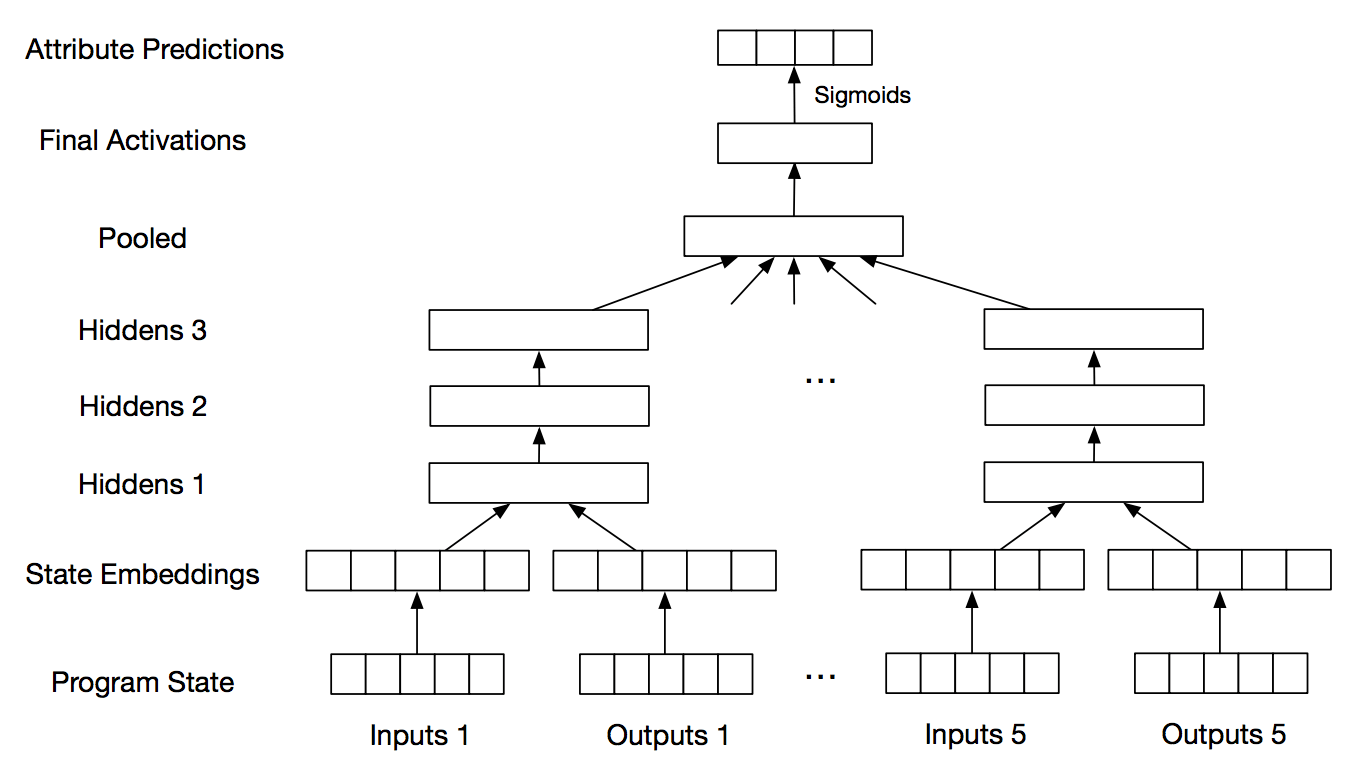
Below, Figure 2 from the paper, is an example of the predicted probability of each DSL function appearing in the source code.
The neural network in this case is particularly interested in trying to use (*4), MAP, FILTER, SORT, and REVERSE to solve the problem.
If the neural network's prediction is accurate, it may possibly find the relevant program quickly and easily without exhaustively searching the program space.

DeepCoder's assistance in directing the search can result in some significant speed-ups over the baseline methods.
Important to note, the maximal length of the programs is length 5, as in the example below.
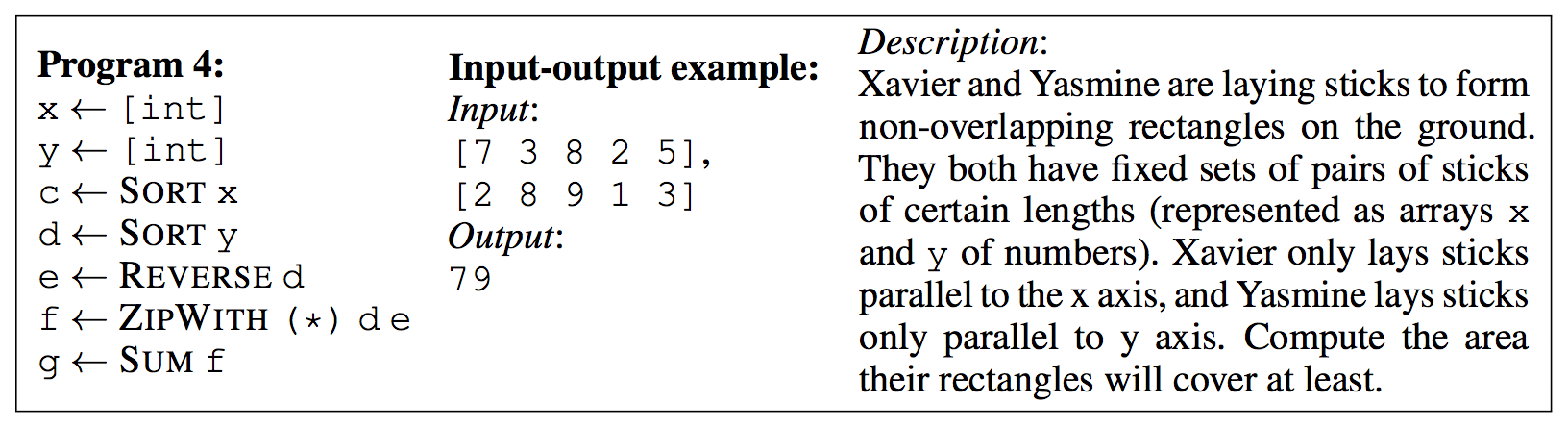
This is still a far cry away from being useful in real world tasks though does represent a strong speed improvement over previous methods that could exhibit these capabilities.
What did people claim DeepCoder could do?
Like a game of telephone / Chinese whispers, errors seem to accumulate in each retelling of scientific research. As this progressed the majority of facts were discarded in favor of a simplistic and inflated narrative such as "DeepCoder copy pastes from Stack Overflow".
Simple statements meant to improve reader comprehension take on a life of their own.
Instead of describing that the program was able to use 34 different first order and higher order functions from a domain specific language (a mouthful and complex concept even for programmers), a journalist may instead describe it as "piecing together lines of code taken from existing software".
Instead of describing the process of training from a specific set of problem descriptions and input / output pairs, a journalist may instead describe it as "using machine learning to scour databases of source code".
Neither of these are bad - especially within the original article context. A full explanation of the paper is out of scope for such an article. These minor simplifications are used to allow a broader audience of readers to follow the story. This is good - more people should have the opportunity to understand these advances.
Many articles are even reasonable in their claims, stating that DeepCoder for now only works with programs of length five or less and specifically only over an extreme subset of programming competition problems. These scoping statements as to the capability of DeepCoder quickly disappear however.
The issue comes as the story is relayed, poorly, over and over again. The incorrect but narratively helpful "piecing together lines of code" suddenly becomes copy and paste. The incorrect but narratively helpful "scouring a database" becomes "stealing from other software" which then jumps to "stealing from StackOverflow". DeepCoder even becomes an active competitor in online programming competitions and capable of already assisting programmers. Reality falls away awfully quickly...
- Microsoft's AI writes code by looting other software
- DeepCoder takes lines of code from existing software
- Microsoft's new AI can code by stealing bits of code from other software
- Microsoft DeepCoder AI Produces Its Own Code By Ripping Off Existing Software
- Microsoft’s AI ‘DeepCoder’ learns coding by stealing from others
- Now, here is DeepCoder, an AI trained to use pieces of code from existing software and write a code of its own.
- DeepCoder AI Writes Programs Using Existing Code Snippets
- DeepCoder builds programs using code it finds lying around
- ...the system works by taking lines of code from existing programs and combining them.
- Thus, the hybrid code was born.
- Called DeepCoder, the software can take requirements by the developer, search through a massive database of code snippets and deliver working code in seconds...
- They only have to describe their program idea and wait for the system to create it.
- It’s been used to complete programming competitions and could be pointed at a larger set of data to build more complex products.
- Once the system knows what a human programmer wants it to accomplish, along with the available inputs, the system can then search more quickly and more completely than any human coder to create a new application.
- DeepCoder successfully plowed through the basic, input-output style challenges usually set by programming competitions.
- In the paper, the researchers explain that DeepCoder relies on big data analysis and machine learning techniques.
- Now it's writing its own code using similar techniques to humans.
To remind you why the above is stunningly incorrect:
- DeepCoder did not (and cannot) at any point take code from another piece of software.
- Stolen implies code was taken illegally and is likely purely added with the intent of clickbaiting.
- DeepCoder can't read or use any of the textual descriptions that might exist for a given problem - so anywhere "reading a problem description" is basically incorrect. Other research has investigated using it but (a) it's not this work and (b) it's not near any level of magic proficiency yet.
- No big data analysis was used - though that is a nice buzz word to add to an article already full of artificial intelligence, machine learning, neural networks, and the rest of the AI hype gang...
- "More quickly and more completely than any human coder" implies superhuman - a popular Terminator-esque narrative which reality is very far from.
What you've seen here only becomes worse as it reaches Twitter or the comment section of various websites... Some knowledgable people might refer to "copying from StackOverflow" as a joke whilst others will misinterpret even the joke as being factual.
Symptoms
- Headlines usually contain far more false content than the article, likely clickbait induced, and it's accepted that reality doesn't need to be represented there
- A small misrepresentation rapidly grows, especially if it can become the bridge that authors use to try to personify the machine learning model, meaning even articles that do good groundwork in ensuring the content is factual can contribute to the eventual molasses
- Factual clarification spreads far slower than clickbait and the majority of articles / comments will only reinforce the fictional narrative
Let's try writing the article
I'm by no means a journalist. My writing above has likely already resulted in a slowly permeating headache radiating from the thinking centres of your brain. With that warning, a journalist friend suggested I "close the loop" by trying to pen an article myself, devoid of fluff. If you're interested in what that looks like, check the bottom of this article.
Thanks to: Christiaan Colen for his stylistic shot of the "Brain" virus from 1986, considered one of the first computer viruses. Like DeepCoder it didn't steal code so it seems appropriate!
AI coding bootcamps? Microsoft / Cambridge teaches DeepCoder to write simple programming challenge solutions
A distant goal of artificial intelligence is to have a system that can solve any task an end user might throw at it. Pass in a well written description of your problem, have a well written program given back to you. If we're being even more grandiose, we might ask the machine learning model to try to improve itself. For now that is very far from reality - but what about challenging artificial intelligence with something a tad simpler?
Programming competition problems are a standard in the industry. Whether programmers tackle these problems for fun, aiming to show their speed and algorithmic knowledge, or whether they're subjected to them as part of a job interview, there's really no escaping them.
Researchers at Microsoft and the University of Cambridge have used examples like these to teach a machine learning model called DeepCoder how to solve simple programming problems. While it's still early days, they've been able to define a simple programming language (a DSL, or domain specific language) that their model can use to program. This programming language doesn't yet have the full flexibility of a standard programming language but it's capable enough of solving many simple programming competition problems.
The concept behind this DSL is relatively intuitive. Imagine an army of monkeys tapping wildy at a QWERTY keyboard trying to reproduce the work of Shakespeare. You'd rightly expect this to take an awfully long time.
What if we gave the monkeys a custom keyboard however? One where we replace the QWERTY characters with only the words we know to appear in Shakespeare's works? We'd expect the monkeys to solve the task quicker - though it'd still be painfully slow.
The last step of DeepCoder's ingenuity is to make some of these keys larger or smaller depending on the context. If our monkeys were tasked to reproduce Romeo and Juliet, there would be two massive keys for "Romeo" and "Juliet", a tiny key for "star-cross'd" (it only ever appears once in the prologue), and no key for "Macbeth" as the famous character is never mentioned in this work.
For now, DeepCoder focuses on just using the input / output pairs to come up with a solution, not even bothering to look at the textual description. By looking for patterns between the input and output - such as all even numbers disappearing at the end or all numbers smaller than 42 disappearing - DeepCoder can guess as to what specific functions might be used to solve the task. With this information, instead of searching over all possible programs that DeepCoder's simple programming language might allow, DeepCoder can far more quickly find a working solution. It verifies such a solution by testing whether the suggested program solves all the example input / output pairs the problem specifies.
Without looking at even the textual description of the problem, DeepCoder has found success tackling many programming challenges with this method. An important note is that it has only tackled problems of five lines so far. This is equivalent to our infinite monkeys being far more successful at crafting individual sentences than paragraphs or chapters. The more keys they have to press, the more opportunities they have to make a mistake.
So are we likely to see the programming competition boards filled with bots spamming solutions soon? Not any time soon. Defining a large number of input / output example pairs is not only required for this task but is quite exhausting. Anyone capable of doing that would likely also be capable of learning to program more efficiently. Additionally, a solution working for the provided input / output pairs gives no guarantee it's an actual working solution. Edge cases catch human programmers all the time even on simple programs even when a humans thoroughly understands a problem descriptions.
While this work by Microsoft and Cambridge researchers is certainly impressive, it's by no means alone. Google have generated code for simulations of Magic the Gathering and Hearthstone by reading card descriptions. Facebook have taught a machine learning model to copy, add, and multiply purely from examples. Many other groups, both in academia and industry, have tackled similar problems.
We'll be sure to tell you which one is the first to tackle an open programming competition such as TopCoder - but for now programmers can rest easy. Or at least rest easy assuming they don't have a job interview with a programming challenge - those things are hard!
So ... where now?
I'll simply restate - the advances in this field are fascinating enough that we don't need to discard reality for the sake of a storyline. I can only hope that both AI-prefix investing and AI-prefix journalism come to terms with this. AI and machine learning will have an immense - hopefully positive - impact on the world. Misrepresenting the capability and limitations of the technology is simply a disservice.
What's the best method to shepherd these stories back towards fact from fiction? I'm honestly not sure. Writing an article like this for every misrepresented paper doesn't seem a scalable solution however. Even listing misrepresented papers or concepts in the media would be exhausting!
I guess I should mediate my complaining at least - the media is helping ensure I've job security until the rolling thunder of the next AI winter comes ;)
Popular Articles
- Peeking into the neural network architecture used for Google's Neural Machine Translation
- It's ML, not magic: machine learning can be prejudiced
- It's ML, not magic: the rise of AI-prefix investing
- In deep learning, architecture engineering is the new feature engineering
- How Google Sparsehash achieves two bits of overhead per entry using sparsetable
- Where did all the HTTP referrers go?
Interested in saying hi? ^_^
Follow @Smerity